Starting today in a new monthly blog post series — imaginatively entitled “A Month In Data” — I will be curating a set of interesting articles, links and resources that I have come across this month relating to data, algorithms, technology and policy: from data science, AI and machine learning, through to ethics, society and governance. This not only reflects my broader academic and policy interests, it also reinforces the increasing impact of data, algorithms and computational processes on our world. Alongside this main list — which is presented in no specific order or precedence — I will also offer a set of short links to posts, academic papers and other relevant resources.
Part I: August 2017
In this first set of posts we have a spread of topics reflecting the breadth of the series — from machine learning, neural nets and NLP, through to data visualisation, predictive policing and data infrastructure policy:
-
I trained an A.I. to generate British placenames
Train an AI on a vast corpus of British place names, then set it loose: from Fuckley and Fapton, to Rastan-on-croan and Stoke of Inch. You might also like: An etymology of AI generated placenames. -
“Fuuuuck”, orthographic repetition on Twitter
An analysis on the usage of “fuck” on Twitter, including regional variation occurrence and sentiment analysis. See detailed post, with data and code available on GitHub.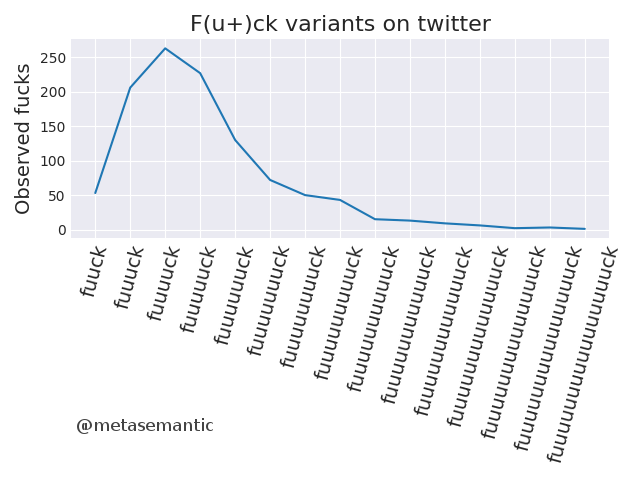
-
Paper: Feeding the Machine: Policing, Crime Data, & Algorithms
This pre-print by Elizabeth E. Joh unpicks the assumption that the police are merely end users of big data; however, they increasingly generate the information that big data programs rely upon. Hence, predictive policing programs cannot be fully understood without an acknowledgment of the role police have in creating its inputs: their choices, priorities, and even omissions become the inputs algorithms use to forecast crime. -
Using chatbots against voicespam: analyzing Lenny’s effectiveness
Lenny is a bot which plays a set of pre-recorded voice messages to interact with spammers. You might be surprised just how simple Lenny actually is — even without any AI or speech recognition mechanism Lenny is able to trick many people and keep conversations going for many minutes (and in one case up to an hour!). Also read the full paper. -
BuzzFeed News Trained A Computer To Search For Hidden Spy Planes. This Is What We Found.
From planes tracking drug traffickers to those testing new spying technology, US airspace is buzzing with surveillance aircraft operated for law enforcement and the military; see the data and code.
-
What makes Bad Figures Bad?
Useful chapter in the forthcoming book Data Visualization for Social Science: A practical introduction with R and ggplot2 by Kieran Healy, which aims to introduce you to both the ideas and the methods of data visualisation in a sensible, comprehensible and reproducible way. -
An Algorithm Summarizes Lengthy Text Surprisingly Well
An algorithm developed by researchers at Salesforce shows how computers may eventually take on the job of summarising documents by using machine learning tricks to produce surprisingly coherent and accurate snippets of text from longer pieces. And while it isn’t yet as good as a person, it hints at how condensing text could eventually become automated. -
Rapid release at massive scale
The software industry has come up with various ways to deliver code faster, safer, and with better quality; many of these efforts centre on ideas such as continuous integration/delivery, agile development, DevOps, and test-driven development. The development and deployment processes at Facebook have grown organically to encompass many parts of these rapid iteration techniques without rigidly adhering to any one in particular. This flexible, pragmatic approach has allowed them to release their web and mobile products successfully on rapid schedules, moving to a quasi-continuous “push from master” system from April 2016.
-
Principles for strengthening our data infrastructure
Data infrastructure underpins business innovation, public services and civil society, but is often broken and neglected. These are the Open Data Institute’s principles to guide how data infrastructure can be strengthened to benefit everyone. -
A visual introduction to machine learning
A useful introductory guide to machine learning, where computers apply statistical learning techniques to automatically identify patterns in data; these techniques can be used to make highly accurate predictions. -
Infographic: Machine learning methods
What’s the right algorithm for the task? This visual primer shows the most common ones in use and the business problems they can solve (also check out two related infographics on an overview of machine learning, as well as its evolution) e.g. random forest algorithms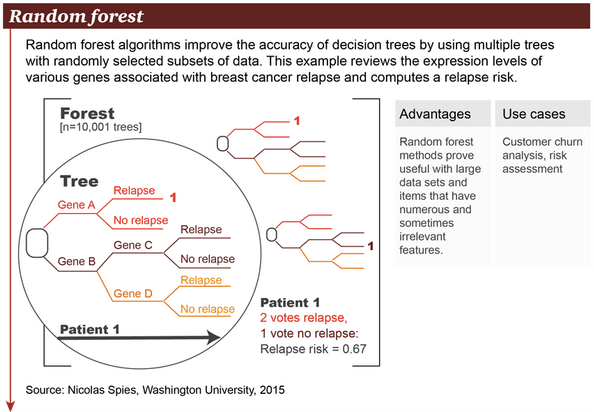
You might also like…
- Mapping accident/collision data: for cars and for cycling
- Air pollution in London: PM2.5 map and exposure data (from the London Datastore)
- AI can predict heart attacks more accurately than doctors
- Know Thy Complexities! (Big O algorithm complexity cheat sheet, plus this post on What is a plain English explanation of “Big O” notation?)
- Paper: Data Rich — But Information Poor by Peter Bernus and Ovidiu Noran
Hopefully I will be able to maintain the monthly frequency of these posts; please comment below with any feedback or recommendations!
(see all other posts in the A Month In Data series)

4 thoughts